
AI training bots are scraping millions of images and web pages daily without explicit permission. Content creators need immediate protection against unauthorized data harvesting.
We at Emplibot see publishers implementing IPTC and robots best practices to regain control over their digital assets. These technical solutions can block specific crawlers while maintaining search engine visibility.
How IPTC and Robots Controls Stop AI Training
IPTC Photo Metadata Standards Block Training at the Source
IPTC Photo Metadata Standards create technical barriers that signal AI training restrictions directly within image files. The IPTC has developed specific guidelines that allow publishers to express data-mining opt-out preferences through embedded metadata that travels with content across platforms.
Publishers can implement the IPTC Photo Metadata Standard with schema.org markup, which attaches copyright notices and usage terms to media content. The Data Mining property within IPTC metadata enables asset-level control, while C2PA-signed images and video files incorporate special assertions for data mining preferences.
Google and Pinterest already recognize IPTC metadata to identify AI-generated images, which proves these standards work in practice. This recognition demonstrates that major platforms respect properly implemented metadata signals.
Robots.txt Configuration Targets Major AI Crawlers
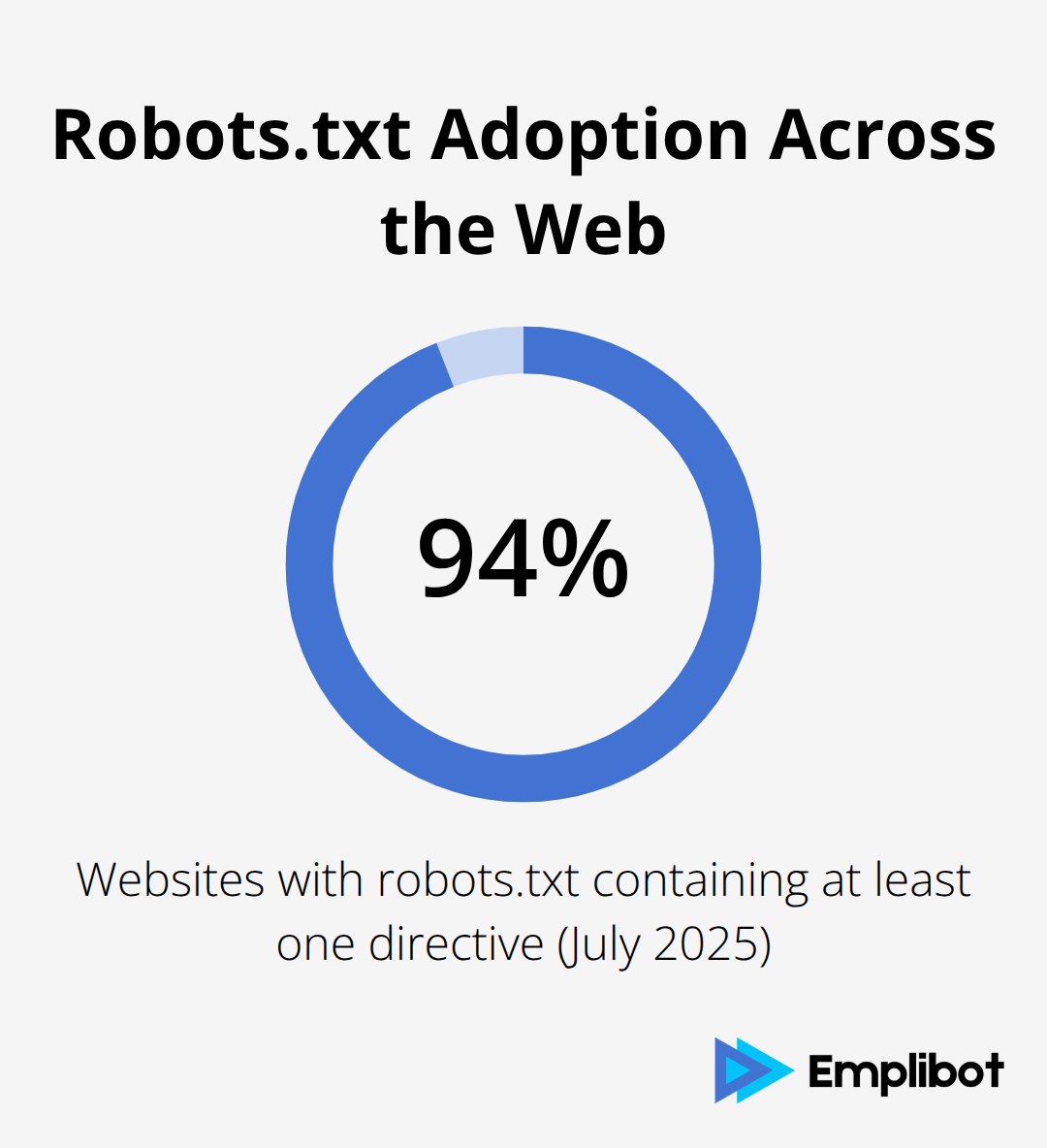
The robots.txt file serves as your first defense against AI training bots. HTTP Archive data from July 2025 shows that 94% of 12 million websites have a robots.txt file containing at least one directive.
GPTBot references skyrocketed from zero to 578,000 sites between August and November 2023. ClaudeBot appearances increased from 2,382 sites in December 2023 to 30,000 by April 2024. These numbers reflect rapid adoption of AI bot blocking measures.

These crawlers behave differently: GPTBot focuses on general web content for ChatGPT training, Google-Extended targets content for Bard and future AI products, and CCBot powers Common Crawl datasets that multiple AI companies use.
Advanced HTTP Headers Override Persistent Crawlers
HTML meta tags and TDMRep specifications offer page-level control when blanket restrictions prove insufficient. X-Robots-Tag HTTP headers send Robots Exclusion Protocol directives directly to crawlers, while TDMRep HTTP versions enable asset-level opt-out restrictions.
Site-wide tdmrep.json files and trust.txt specifications with datatrainingallowed=no commands provide additional layers of protection beyond standard robots.txt directives. These methods work together to create multiple checkpoints that responsible crawlers must respect.
Internet firewalls can block AI crawler bots that ignore robots.txt files entirely (though this requires identifying specific user-agent IDs for each AI system). Some crawlers deliberately ignore these signals, which makes server-level implementation essential for your next line of defense.
How Do You Implement IPTC Metadata Protection
Embed AI Training Restrictions in Image Files
IPTC metadata implementation requires direct embedding within image files through the Data Mining property field. Set the value to “prohibited” to signal AI training restrictions at the asset level. Adobe Lightroom and Photoshop support IPTC metadata editing through their Rights Management panels, while command-line tools like ExifTool offer batch processing capabilities.
Professional photographers access IPTC fields through File > File Info > IPTC Extension tab in Adobe Creative Suite. Add your copyright notice, usage terms, and set Data Mining to prohibited. ExifTool processes entire directories with commands like exiftool -IPTC:DataMining=prohibited *.jpg for bulk operations. WordPress users install plugins like WP Media Folder that automatically apply IPTC metadata to uploaded images.
The metadata travels with images across platforms, which makes this protection method platform-independent. Major platforms like Google and Pinterest already recognize these embedded signals and respect the training restrictions they contain.
Implement Server-Side Schema.org Markup
Schema.org markup amplifies IPTC protection and makes metadata machine-readable at the HTML level. Insert this code snippet in your image containers:
html
<div itemscope itemtype=”https://schema.org/ImageObject”>
<meta itemprop=”copyrightNotice” content=”All rights reserved – AI training prohibited”>
<img src=”image.jpg” itemprop=”contentUrl”>
</div>
Content management systems benefit from automated schema implementation. WordPress themes integrate this markup through functions.php modifications, while custom CMS solutions require template-level changes. The schema markup works alongside embedded IPTC data to create redundant protection layers that responsible AI systems recognize.
Configure Rights Management Systems
Enterprise-level protection demands centralized rights management through digital asset management platforms. Widen Collective and Bynder offer IPTC metadata automation that applies consistent copyright notices across asset libraries. These systems generate C2PA-signed images with embedded training restrictions.
Configure your DAM system to automatically append AI training prohibitions to all uploaded assets. Most enterprise platforms support bulk metadata application through CSV imports or API integrations (eliminating manual metadata entry while maintaining consistent protection across thousands of files).
This systematic approach creates the foundation for your next defense layer: advanced bot control strategies that work at the server level to block persistent crawlers that ignore metadata signals entirely.
How Do You Block Persistent AI Crawlers
Firewall Configuration Targets Specific User Agents
Apache servers require .htaccess modifications to block AI crawlers that ignore robots.txt directives. Add these rules to deny access to GPTBot, Google-Extended, and CCBot through their user-agent strings:
RewriteCond %{HTTP_USER_AGENT} ^.*GPTBot.*$ [NC]
RewriteRule ^.*$ – [F,L]
RewriteCond %{HTTP_USER_AGENT} ^.*Google-Extended.*$ [NC]
RewriteRule ^.*$ – [F,L]
RewriteCond %{HTTP_USER_AGENT} ^.*CCBot.*$ [NC]
RewriteRule ^.*$ – [F,L]
Windows IIS servers achieve similar results through web.config files with system.webServer/rewrite/rules sections that match user-agent patterns. These rules return 403 Forbidden responses to unauthorized crawlers.
Cloudflare WAF Rules Block Enterprise-Level Threats
Cloudflare WAF rules provide advanced protection against persistent crawlers. Create custom rules that examine request headers for known AI bot signatures, then apply block actions to match traffic patterns. Navigate to Security > WAF > Custom Rules and add expressions like (http.user_agent contains “GPTBot”) with Block action selected.
Configure rate limits that trigger when crawlers exceed normal access patterns (typically more than 10 requests per minute from single IP addresses). These firewall approaches work when metadata and robots.txt signals fail to deter unauthorized data collection.
Monthly Access Log Analysis Reveals Bot Activity
Server access logs contain essential data for tracking AI crawler behavior and protection effectiveness. Parse your logs monthly for user-agent strings that contain GPTBot, ChatGPT-User, CCBot, or Google-Extended patterns.

Logwatch provides automated log analysis that identifies crawler traffic volumes and success rates against your blocks.
Focus your analysis on HTTP status codes returned to AI crawlers. Status 200 responses indicate successful content access, while 403 or 404 codes show effective blocks. Monitor bandwidth consumption from AI traffic, which often exceeds normal visitor patterns due to systematic content harvesting.
Server-Level Configuration Options
Nginx servers block AI crawlers through location blocks in your configuration file. Add if ($http_user_agent ~* “GPTBot|Google-Extended|CCBot”) { return 403; } within your server block to deny access. This method works at the web server level before requests reach your application.
Consider IP-based restrictions for persistent crawlers that rotate user-agent strings. Some AI services operate from known IP ranges that you can block entirely through iptables rules or cloud provider security groups. Adjust your firewall rules based on new crawler patterns, as AI services regularly deploy different user-agent identifications that bypass existing protections.
Final Thoughts
Current IPTC and robots best practices provide solid protection against responsible AI crawlers, but significant gaps remain. Some crawlers deliberately ignore robots.txt directives and metadata signals, which means your content remains vulnerable despite proper implementation. The reality shows that opt-out methods work only when AI companies choose to respect them.
Search engine visibility requires careful balance when you implement these restrictions. Block AI training bots while you allow legitimate crawlers like Googlebot and Bingbot to maintain your SEO rankings. Your robots.txt file should target specific AI user-agents rather than blanket restrictions that harm search performance.
Future protection demands constant vigilance as new AI crawlers emerge monthly (with services like Perplexity deploying undeclared crawlers that bypass standard protections). Monitor your server logs regularly and update firewall rules when new bot patterns appear. We at Emplibot help you focus on strategy while Emplibot automates your WordPress blog and social media through keyword research, content creation, and SEO optimization.








